 The Spring AI ChatClient offers a fluent API for communicating with an AI model.
The fluent API provides methods for building the constituent parts of a prompt that gets passed to the AI model as input.
Advisors are a key part of the fluent API that intercept, modify, and enhance AI-driven interactions.
The key benefits include encapsulating common Generative AI patterns, transforming data sent to and from Large Language Models (LLMs), and providing portability across various models and use cases.
Advisors process
The Spring AI ChatClient offers a fluent API for communicating with an AI model.
The fluent API provides methods for building the constituent parts of a prompt that gets passed to the AI model as input.
Advisors are a key part of the fluent API that intercept, modify, and enhance AI-driven interactions.
The key benefits include encapsulating common Generative AI patterns, transforming data sent to and from Large Language Models (LLMs), and providing portability across various models and use cases.
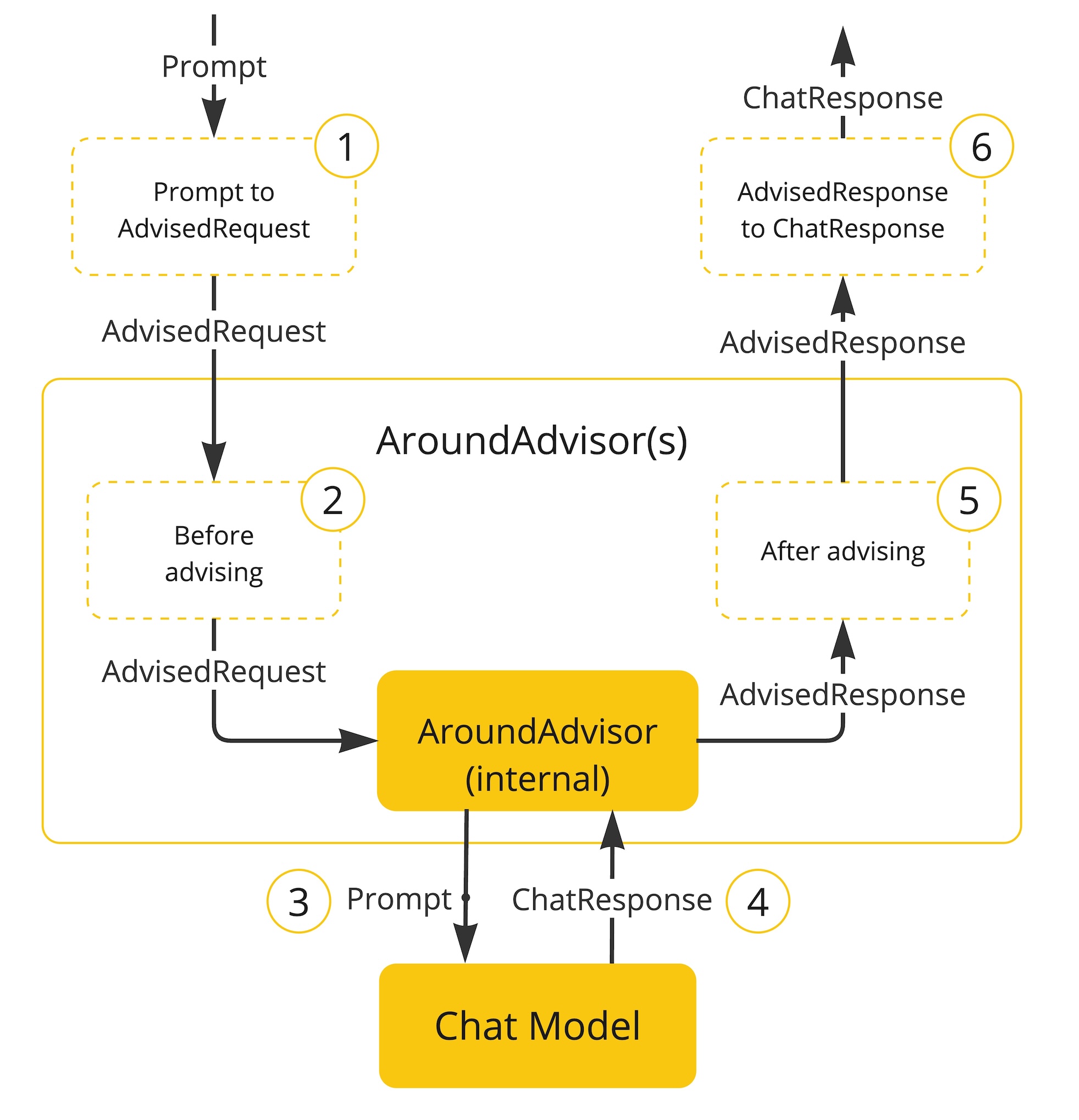
Advisors process ChatClientRequest and ChatClientResponse objects.
The framework chains advisors by their getOrder() values (lower values execute first), with the final advisor calling the LLM.
Spring AI provides built-in advisors for Conversation Memory, Retrieval Augmented Generation (RAG), Logging, and Guardrails. Developers can also create custom advisors.
Typical advisor structure:
Recursive Advisors
Starting with version
1.1.0-M4, Spring AI introduces Recursive Advisors, enabling looping through the advisor chain multiple times to support iterative workflows:- Tool calling loops: Executing multiple tools in sequence, where each tool’s output informs the next decision
- Output validation: Validating structured responses and retrying with feedback when validation fails
- Retry logic: Refining requests based on response quality or external criteria
- Evaluation flows: Evaluating and modifying responses before delivery
- Agentic loops: Building autonomous agents that plan, execute, and iterate on tasks by analyzing results and determining next actions until a goal is achieved
CallAdvisorChain.copy(CallAdvisor after) method creates a sub-chain containing only downstream advisors, enabling controlled iteration while maintaining proper ordering and observability, and preventing re-execution of upstream advisors.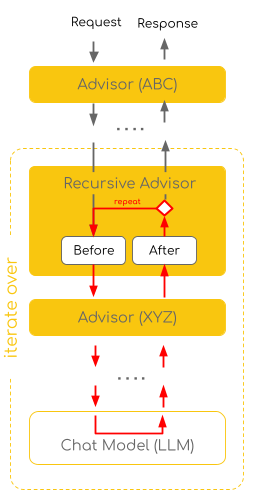
The diagram illustrates how recursive advisors enable iterative processing by allowing the flow to loop back through the advisor chain multiple times. Unlike traditional single-pass execution, recursive advisors can revisit previous advisors based on response conditions, creating sophisticated iterative workflows between the client, advisors, and LLM.
chain.copy(this).nextCall(...) instead of chain.nextCall(...) to iterate on a copy of the inner chain.
This ensures each iteration goes through the complete downstream chain, allowing other advisors to observe and intercept while maintaining proper observability.
⚠️ Important Note
Recursive Advisors are a new experimental feature in Spring AI 1.1.0-M4. They are non-streaming only, requires careful advisor ordering, can increase costs due to multiple LLM calls. Be especially careful with inner advisors that maintain external state - they may require extra attention to maintain correctness across iterations. Always set termination conditions and retry limits to prevent infinite loops. Consider whether your use case benefits more from recursive advisors or from implementing an explicit while loop around ChatClient calls in your application code.
Built-in Recursive Advisors
Spring AI 1.1.0-M4 provides two recursive advisors:ToolCallAdvisor
Default ToolCalling supportBy default, the Spring AI Tool Execution is implemented inside each 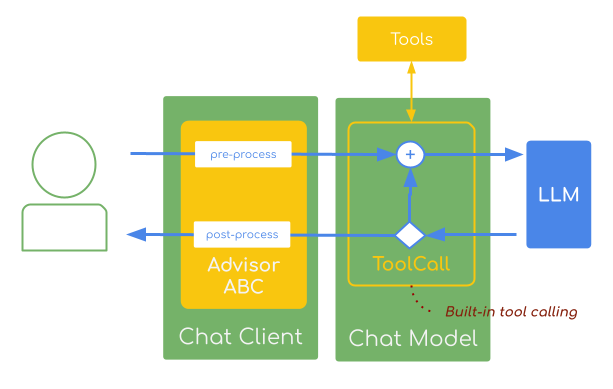
ChatModel implementation using a ToolCallingManager.
This means that the tool calling requests and response flow is opaque for the ChatClient Advisors as it happens outside the advisor execution chain.ToolCallAdvisorLeveraging the User-Controlled tool execution, the 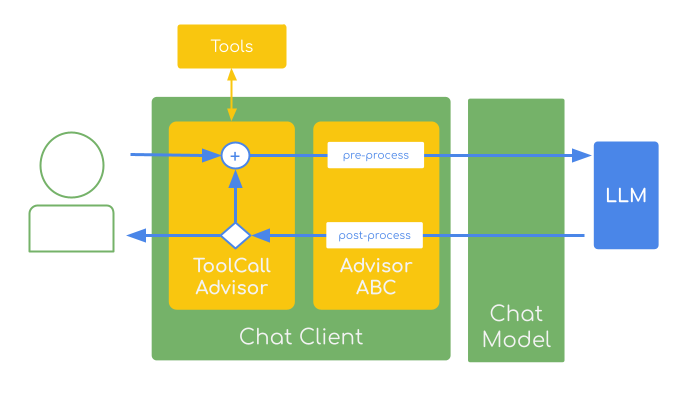
ToolCallAdvisor implements the tool calling loop within the advisor chain, providing explicit control over tool execution rather than delegating to the model’s internal tool execution- Loops until no more tool calls are present
- Enables other advisors (such as Advisor ABC) to intercept and alter each tool call request and response
- Supports “return direct” functionality
- Disables the chat-model’s internal tool execution
Ordered.HIGHEST_PRECEDENCE to ensure the advisor executes first in the chain (first for request processing, last for response processing), allowing inner advisors to intercept and process tool request and response messages.
When a tool execution has returnDirect=true, the advisor executes the tool, detects the flag, breaks the loop, and returns the output directly to the client without sending it to the LLM. This reduces latency when the tool’s output is the final answer.
💡 Demo Project: See a complete working example of the ToolCallAdvisor in the Recursive Advisor Demo project.
StructuredOutputValidationAdvisor
TheStructuredOutputValidationAdvisor validates structured JSON output against a generated schema and retries if validation fails:
- Automatically generates JSON schemas from expected output types
- Validates LLM responses againsts the schema and retries with validation error messages
- Configurable maximum retry attempts
- Supports custom
ObjectMapperfor JSON processing
Ordered.LOWEST_PRECEDENCE to ensure the advisor executes toward the end of the chain (but before the model call), meaning it’s last for request processing and first for response processing.
Best Practices
- Set Clear Termination Conditions: Ensure loops have definite exit conditions to prevent infinite loops
- Use Appropriate Ordering: Place recursive advisors early in the chain to allow other advisors to observe iterations, or late to prevent observation
- Provide Feedback: Augment retry requests with information about why the retry is needed to help the LLM improve
- Limit Iterations: Set maximum attempt limits to prevent runaway execution
- Monitor Execution: Use Spring AI’s observability features to track iteration counts and performance
- Choose the Right Approach: Evaluate whether recursive advisors or explicit while loops around ChatClient calls better suit your specific use case and architecture
Performance Considerations
Recursive advisors increase the number of LLM calls, affecting:- Cost: More API calls increase costs
- Latency: Multiple iterations add processing time
- Token Usage: Each iteration consumes additional tokens