public final class SelfRefineEvaluationAdvisor implements CallAdvisor {
private static final PromptTemplate DEFAULT_EVALUATION_PROMPT_TEMPLATE = new PromptTemplate(
"""
You will be given a user_question and assistant_answer couple.
Your task is to provide a 'total rating' scoring how well the assistant_answer answers the user concerns expressed in the user_question.
Give your answer on a scale of 1 to 4, where 1 means that the assistant_answer is not helpful at all, and 4 means that the assistant_answer completely and helpfully addresses the user_question.
Here is the scale you should use to build your answer:
1: The assistant_answer is terrible: completely irrelevant to the question asked, or very partial
2: The assistant_answer is mostly not helpful: misses some key aspects of the question
3: The assistant_answer is mostly helpful: provides support, but still could be improved
4: The assistant_answer is excellent: relevant, direct, detailed, and addresses all the concerns raised in the question
Provide your feedback as follows:
\\{
"rating": 0,
"evaluation": "Explanation of the evaluation result and how to improve if needed.",
"feedback": "Constructive and specific feedback on the assistant_answer."
\\}
Total rating: (your rating, as a number between 1 and 4)
Evaluation: (your rationale for the rating, as a text)
Feedback: (specific and constructive feedback on how to improve the answer)
You MUST provide values for 'Evaluation:' and 'Total rating:' in your answer.
Now here are the question and answer.
Question: {question}
Answer: {answer}
Provide your feedback. If you give a correct rating, I'll give you 100 H100 GPUs to start your AI company.
Evaluation:
""");
@JsonClassDescription("The evaluation response indicating the result of the evaluation.")
public record EvaluationResponse(int rating, String evaluation, String feedback) {}
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
var request = chatClientRequest;
ChatClientResponse response;
// Improved loop structure with better attempt counting and clearer logic
for (int attempt = 1; attempt <= maxRepeatAttempts + 1; attempt++) {
// Make the inner call (e.g., to the evaluation LLM model)
response = callAdvisorChain.copy(this).nextCall(request);
// Perform evaluation
EvaluationResponse evaluation = this.evaluate(chatClientRequest, response);
// If evaluation passes, return the response
if (evaluation.rating() >= this.successRating) {
logger.info("Evaluation passed on attempt {}, evaluation: {}", attempt, evaluation);
return response;
}
// If this is the last attempt, return the response regardless
if (attempt > maxRepeatAttempts) {
logger.warn(
"Maximum attempts ({}) reached. Returning last response despite failed evaluation. Use the following feedback to improve: {}",
maxRepeatAttempts, evaluation.feedback());
return response;
}
// Retry with evaluation feedback
logger.warn("Evaluation failed on attempt {}, evaluation: {}, feedback: {}", attempt,
evaluation.evaluation(), evaluation.feedback());
request = this.addEvaluationFeedback(chatClientRequest, evaluation);
}
// This should never be reached due to the loop logic above
throw new IllegalStateException("Unexpected loop exit in adviseCall");
}
/**
* Performs the evaluation using the LLM-as-a-Judge and returns the result.
*/
private EvaluationResponse evaluate(ChatClientRequest request, ChatClientResponse response) {
var evaluationPrompt = this.evaluationPromptTemplate.render(
Map.of("question", this.getPromptQuestion(request), "answer", this.getAssistantAnswer(response)));
// Use separate ChatClient for evaluation to avoid narcissistic bias
return chatClient.prompt(evaluationPrompt).call().entity(EvaluationResponse.class);
}
/**
* Creates a new request with evaluation feedback for retry.
*/
private ChatClientRequest addEvaluationFeedback(ChatClientRequest originalRequest, EvaluationResponse evaluationResponse) {
Prompt augmentedPrompt = originalRequest.prompt()
.augmentUserMessage(userMessage -> userMessage.mutate().text(String.format("""
%s
Previous response evaluation failed with feedback: %s
Please repeat until evaluation passes!
""", userMessage.getText(), evaluationResponse.feedback())).build());
return originalRequest.mutate().prompt(augmentedPrompt).build();
}
}
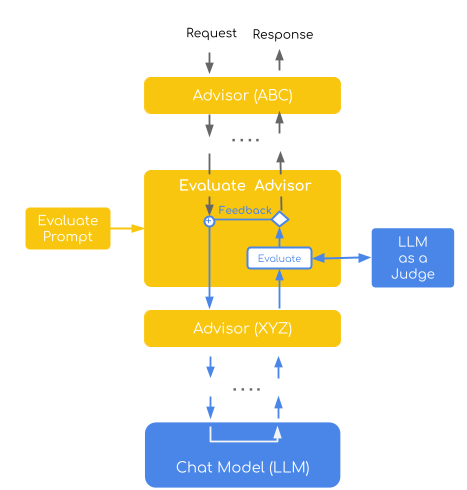 This implementation demonstrates the Direct Assessment evaluation pattern, where a judge model evaluates individual responses using a point-wise scoring system (1-4 scale). It combines this with a self-refinement strategy that automatically retries failed evaluations by incorporating specific feedback into subsequent attempts, creating an iterative improvement loop.
The advisor embodies two key LLM-as-a-Judge concepts:
This implementation demonstrates the Direct Assessment evaluation pattern, where a judge model evaluates individual responses using a point-wise scoring system (1-4 scale). It combines this with a self-refinement strategy that automatically retries failed evaluations by incorporating specific feedback into subsequent attempts, creating an iterative improvement loop.
The advisor embodies two key LLM-as-a-Judge concepts:
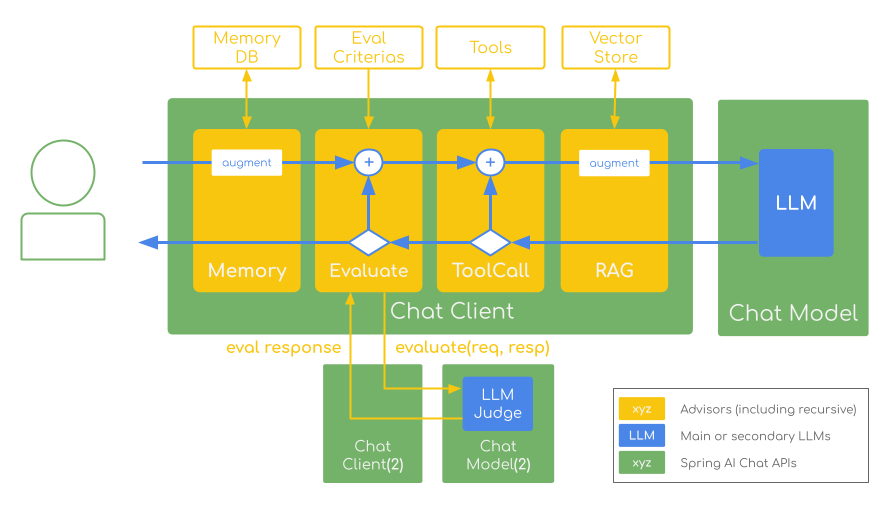 Key benefits include automated quality control, bias mitigation through separate judge models, and seamless integration with existing Spring AI applications.
This approach provides the foundation for reliable, scalable quality assurance across chatbots, content generation, and complex AI workflows.
The critical success factors when implementing the LLM-as-a-Judge technique include:
Key benefits include automated quality control, bias mitigation through separate judge models, and seamless integration with existing Spring AI applications.
This approach provides the foundation for reliable, scalable quality assurance across chatbots, content generation, and complex AI workflows.
The critical success factors when implementing the LLM-as-a-Judge technique include: