 The examples and patterns in this article are based on the comprehensive Prompt Engineering Guide that covers the theory, principles, and patterns of effective prompt engineering.
The blog shows how to translate those concepts into working Java code using Spring AI’s fluent ChatClient API.
For convenience, the examples are structured to follow the same patterns and techniques outlined in the original guide.
The demo source code used in this article is available at: https://github.com/spring-projects/spring-ai-examples/tree/main/prompt-engineering/prompt-engineering-patterns
The examples and patterns in this article are based on the comprehensive Prompt Engineering Guide that covers the theory, principles, and patterns of effective prompt engineering.
The blog shows how to translate those concepts into working Java code using Spring AI’s fluent ChatClient API.
For convenience, the examples are structured to follow the same patterns and techniques outlined in the original guide.
The demo source code used in this article is available at: https://github.com/spring-projects/spring-ai-examples/tree/main/prompt-engineering/prompt-engineering-patterns
1. Configuration
The configuration section outlines how to set up and tune your Large Language Model (LLM) with Spring AI. It covers selecting the right LLM provider for your use case and configuring important generation parameters that control the quality, style, and format of model outputs.LLM Provider Selection
For prompt engineering, you will start by choosing a model. Spring AI supports multiple LLM providers (such as OpenAI, Anthropic, Google Vertex AI, AWS Bedrock, Ollama, and more), letting you switch providers without changing application code—just update your configuration. Just add the selected starter dependencyspring-ai-starter-model-<MODEL-PROVIDER-NAME>.
For example, here is how to enable Anthropic Claude API:
spring.ai.anthropic.api-key=${ANTHROPIC_API_KEY}
You can specify a particular LLM model name like this:
LLM Output Configuration
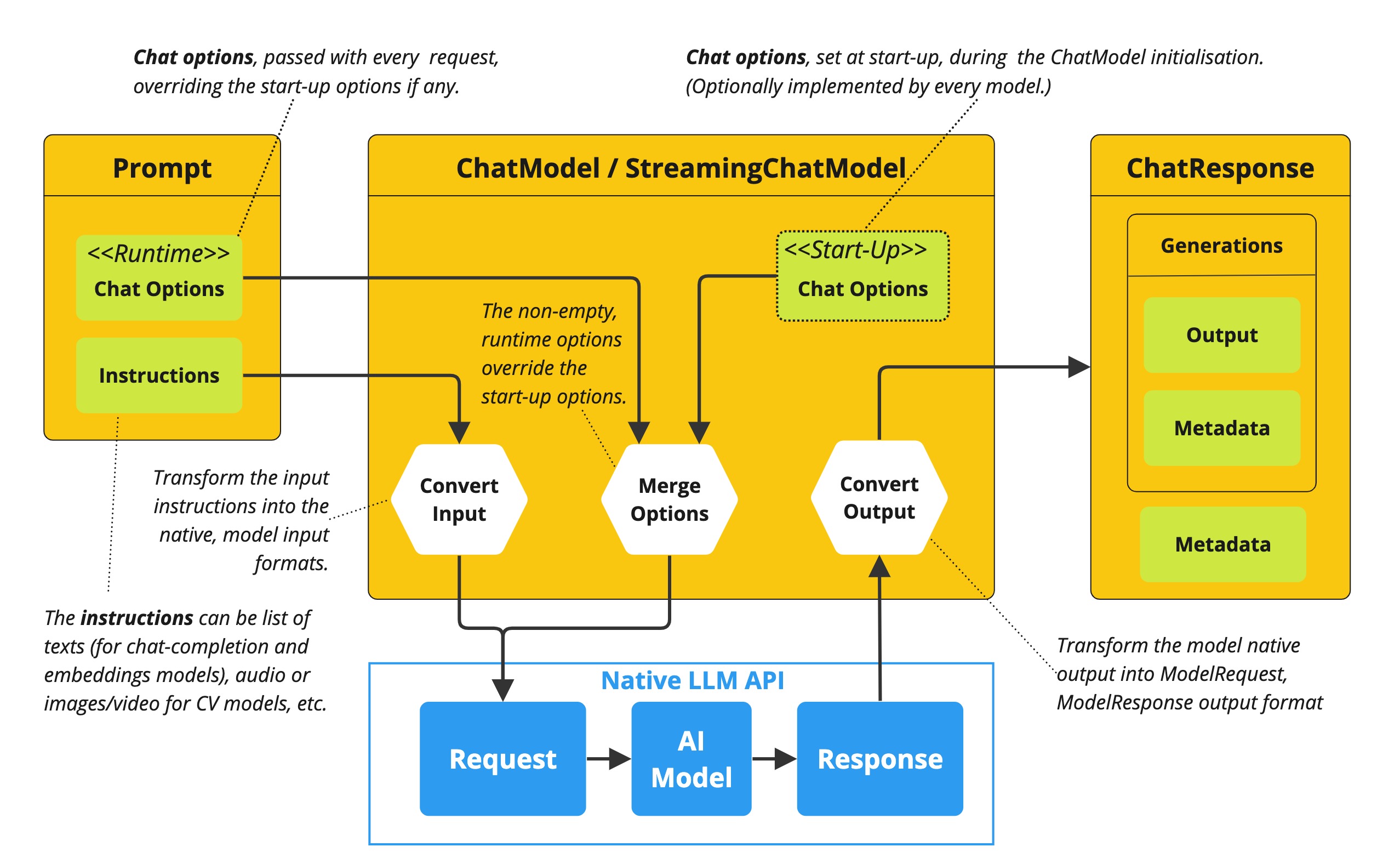 Before we dive into prompt engineering techniques, it’s essential to understand how to configure the LLM’s output behavior. Spring AI provides several configuration options that let you control various aspects of generation through the ChatOptions builder.
All configurations can be applied programmatically as demonstrated in the examples below or through Spring application properties at start time.
Before we dive into prompt engineering techniques, it’s essential to understand how to configure the LLM’s output behavior. Spring AI provides several configuration options that let you control various aspects of generation through the ChatOptions builder.
All configurations can be applied programmatically as demonstrated in the examples below or through Spring application properties at start time.
Temperature
Temperature controls the randomness or “creativity” of the model’s response.- Lower values (0.0-0.3): More deterministic, focused responses. Better for factual questions, classification, or tasks where consistency is critical.
- Medium values (0.4-0.7): Balanced between determinism and creativity. Good for general use cases.
- Higher values (0.8-1.0): More creative, varied, and potentially surprising responses. Better for creative writing, brainstorming, or generating diverse options.
Output Length (MaxTokens)
ThemaxTokens parameter limits how many tokens (word pieces) the model can generate in its response.
- Low values (5-25): For single words, short phrases, or classification labels.
- Medium values (50-500): For paragraphs or short explanations.
- High values (1000+): For long-form content, stories, or complex explanations.
Sampling Controls (Top-K and Top-P)
These parameters give you fine-grained control over the token selection process during generation.- Top-K: Limits token selection to the K most likely next tokens. Higher values (e.g., 40-50) introduce more diversity.
- Top-P (nucleus sampling): Dynamically selects from the smallest set of tokens whose cumulative probability exceeds P. Values like 0.8-0.95 are common.
Structured Response Format
Along with the plain text response (using.content()), Spring AI makes it easy to directly map LLM responses to Java objects using the .entity() method.
Model-Specific Options
While the portableChatOptions provides a consistent interface across different LLM providers, Spring AI also offers model-specific options classes that expose provider-specific features and configurations. These model-specific options allow you to leverage the unique capabilities of each LLM provider.
OpenAiChatOptions, AnthropicChatOptions, MistralAiChatOptions) that exposes provider-specific parameters while still implementing the common interface. This approach gives you the flexibility to use portable options for cross-provider compatibility or model-specific options when you need access to unique features of a particular provider.
Note that when using model-specific options, your code becomes tied to that specific provider, reducing portability. It’s a trade-off between accessing advanced provider-specific features versus maintaining provider independence in your application.
2. Prompt Engineering Techniques
Each section below implements a specific prompt engineering technique from the guide. By following both the “Prompt Engineering” guide and these implementations, you’ll develop a thorough understanding of not just what prompt engineering techniques are available, but how to effectively implement them in production Java applications.2.1 Zero-Shot Prompting
Zero-shot prompting involves asking an AI to perform a task without providing any examples. This approach tests the model’s ability to understand and execute instructions from scratch. Large language models are trained on vast corpora of text, allowing them to understand what tasks like “translation,” “summarization,” or “classification” entail without explicit demonstrations. Zero-shot is ideal for straightforward tasks where the model likely has seen similar examples during training, and when you want to minimize prompt length. However, performance may vary depending on task complexity and how well the instructions are formulated..entity(Sentiment.class) mapping to a Java enum.
Reference: Brown, T. B., et al. (2020). “Language Models are Few-Shot Learners.” arXiv:2005.14165. https://arxiv.org/abs/2005.14165
2.2 One-Shot & Few-Shot Prompting
Few-shot prompting provides the model with one or more examples to help guide its responses, particularly useful for tasks requiring specific output formats. By showing the model examples of desired input-output pairs, it can learn the pattern and apply it to new inputs without explicit parameter updates. One-shot provides a single example, which is useful when examples are costly or when the pattern is relatively simple. Few-shot uses multiple examples (typically 3-5) to help the model better understand patterns in more complex tasks or to illustrate different variations of correct outputs.2.3 System, contextual and role prompting
System Prompting
System prompting sets the overall context and purpose for the language model, defining the “big picture” of what the model should be doing. It establishes the behavioral framework, constraints, and high-level objectives for the model’s responses, separate from the specific user queries. System prompts act as a persistent “mission statement” throughout the conversation, allowing you to set global parameters like output format, tone, ethical boundaries, or role definitions. Unlike user prompts which focus on specific tasks, system prompts frame how all user prompts should be interpreted.Role Prompting
Role prompting instructs the model to adopt a specific role or persona, which affects how it generates content. By assigning a particular identity, expertise, or perspective to the model, you can influence the style, tone, depth, and framing of its responses. Role prompting leverages the model’s ability to simulate different expertise domains and communication styles. Common roles include expert (e.g., “You are an experienced data scientist”), professional (e.g., “Act as a travel guide”), or stylistic character (e.g., “Explain like you’re Shakespeare”).Contextual Prompting
Contextual prompting provides additional background information to the model by passing context parameters. This technique enriches the model’s understanding of the specific situation, enabling more relevant and tailored responses without cluttering the main instruction. By supplying contextual information, you help the model understand the specific domain, audience, constraints, or background facts relevant to the current query. This leads to more accurate, relevant, and appropriately framed responses.2.4 Step-Back Prompting
Step-back prompting breaks complex requests into simpler steps by first acquiring background knowledge. This technique encourages the model to first “step back” from the immediate question to consider the broader context, fundamental principles, or general knowledge relevant to the problem before addressing the specific query. By decomposing complex problems into more manageable components and establishing foundational knowledge first, the model can provide more accurate responses to difficult questions.2.5 Chain of Thought (CoT)
Chain of Thought prompting encourages the model to reason step-by-step through a problem, which improves accuracy for complex reasoning tasks. By explicitly asking the model to show its work or think through a problem in logical steps, you can dramatically improve performance on tasks requiring multi-step reasoning. CoT works by encouraging the model to generate intermediate reasoning steps before producing a final answer, similar to how humans solve complex problems. This makes the model’s thinking process explicit and helps it arrive at more accurate conclusions.2.6 Self-Consistency
Self-consistency involves running the model multiple times and aggregating results for more reliable answers. This technique addresses the variability in LLM outputs by sampling diverse reasoning paths for the same problem and selecting the most consistent answer through majority voting. By generating multiple reasoning paths with different temperature or sampling settings, then aggregating the final answers, self-consistency improves accuracy on complex reasoning tasks. It’s essentially an ensemble method for LLM outputs.2.7 Tree of Thoughts (ToT)
Tree of Thoughts (ToT) is an advanced reasoning framework that extends Chain of Thought by exploring multiple reasoning paths simultaneously. It treats problem-solving as a search process where the model generates different intermediate steps, evaluates their promise, and explores the most promising paths. This technique is particularly powerful for complex problems with multiple possible approaches or when the solution requires exploring various alternatives before finding the optimal path.NOTE: The original “Prompt Engineering” guide doesn’t provide implementation examples for ToT, likely due to its complexity. Below is a simplified example that demonstrates the core concept.Game Solving ToT Example:
2.8 Automatic Prompt Engineering
Automatic Prompt Engineering uses the AI to generate and evaluate alternative prompts. This meta-technique leverages the language model itself to create, refine, and benchmark different prompt variations to find optimal formulations for specific tasks. By systematically generating and evaluating prompt variations, APE can find more effective prompts than manual engineering, especially for complex tasks. It’s a way of using AI to improve its own performance.2.9 Code Prompting
Code prompting refers to specialized techniques for code-related tasks. These techniques leverage LLMs’ ability to understand and generate programming languages, enabling them to write new code, explain existing code, debug issues, and translate between languages. Effective code prompting typically involves clear specifications, appropriate context (libraries, frameworks, style guidelines), and sometimes examples of similar code. Temperature settings tend to be lower (0.1-0.3) for more deterministic outputs.Conclusion
Spring AI provides an elegant Java API for implementing all major prompt engineering techniques. By combining these techniques with Spring’s powerful entity mapping and fluent API, developers can build sophisticated AI-powered applications with clean, maintainable code. The most effective approach often involves combining multiple techniques—for example, using system prompts with few-shot examples, or chain-of-thought with role prompting. Spring AI’s flexible API makes these combinations straightforward to implement. For production applications, remember to:- Test prompts with different parameters (temperature, top-k, top-p)
- Consider using self-consistency for critical decision-making
- Leverage Spring AI’s entity mapping for type-safe responses
- Use contextual prompting to provide application-specific knowledge
References
- Brown, T. B., et al. (2020). “Language Models are Few-Shot Learners.” arXiv:2005.14165.
- Wei, J., et al. (2022). “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” arXiv:2201.11903.
- Wang, X., et al. (2022). “Self-Consistency Improves Chain of Thought Reasoning in Language Models.” arXiv:2203.11171.
- Yao, S., et al. (2023). “Tree of Thoughts: Deliberate Problem Solving with Large Language Models.” arXiv:2305.10601.
- Zhou, Y., et al. (2022). “Large Language Models Are Human-Level Prompt Engineers.” arXiv:2211.01910.
- Zheng, Z., et al. (2023). “Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models.” arXiv:2310.06117.
- Liu, P., et al. (2021). “What Makes Good In-Context Examples for GPT-3?” arXiv:2101.06804.
- Shanahan, M., et al. (2023). “Role-Play with Large Language Models.” arXiv:2305.16367.
- Chen, M., et al. (2021). “Evaluating Large Language Models Trained on Code.” arXiv:2107.03374.
- Spring AI Documentation
- ChatClient API Reference
- Google’s Prompt Engineering Guide